虽然文本到图像(T2I)生成模型已经变得无处不在,但它们不一定生成与给定提示相符的图像。虽然之前的工作通过提出用于收集人类判断的指标、基准和模板来评估 T2I 一致性,但这些组件的质量并未得到系统测量。人工评分的提示集通常很小,并且不会评估评分的可靠性以及用于比较模型的提示集。
我们通过评估自动评估指标和人工模板进行广泛的研究来解决这一差距。我们提供了三个主要贡献:
- (1)我们引入了一个基于技能的综合基准,可以区分不同人类模板的模型。这种基于技能的基准将提示分类为子技能,使从业者不仅可以查明哪些技能具有挑战性,还可以查明该技能在何种复杂程度下变得具有挑战性。
- (2) 我们收集了四个模板和四个 T2I 模型的人类评分,总计超过 100K 个注释。这使我们能够了解由于提示中固有的模糊性而产生的差异以及由于指标和模型质量的差异而产生的差异。
- (3) 最后,我们引入了一种新的基于 QA 的自动评估指标,与新数据集、跨不同人工模板以及 TIFA160 上的现有指标相比,该指标与人工评分的相关性更好。
数据和代码:https://github.com/google-deepmind/gecko_benchmark_t2i
一、简介
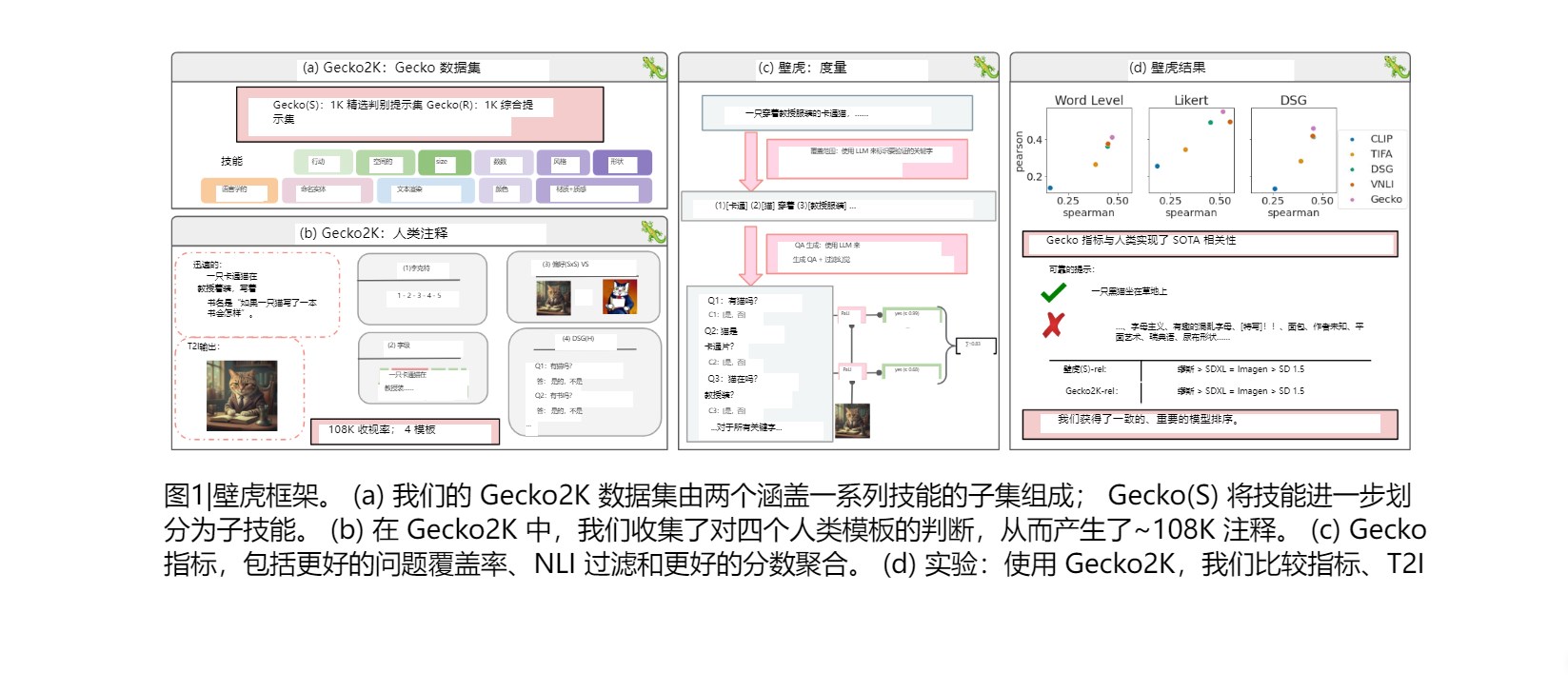
虽然文本到图像 (T2I) 模型 [51、63、3、50] 生成质量令人印象深刻的图像,但生成的图像不一定正确捕获给定提示的所有方面。请参见图 1 的面板 (b),这是一个高质量生成图像的示例,该图像未完全捕获提示“卡通穿着教授服装的猫正在写一本标题为“如果一只猫写了一本书怎么办?”的书。
值得注意的是,可靠地评估图像和提示之间的对应关系(称为它们的对齐)仍然是一个悬而未决的问题,需要三个步骤:(1)创建提示集,(2)设计实验来收集人类判断,以及(3)开发衡量图像文本对齐的指标,我们依次讨论每个步骤以及如何解决先前工作的缺点。
提示设置。要彻底评估 T2I 模型,提示的选择至关重要,因为它定义了要评估的各种能力或技能;在上面的示例中,对模型进行了对齐测试,需要动作理解、样式理解和文本渲染。之前的工作通过将从现有视觉语言数据集中获取的提示分组为高级类别(例如推理)来整理数据集[35]。然而,现有的数据集并未涵盖具有不同复杂程度的一系列技能,并且可能会同时测试几种技能。我们通过开发 Gecko2K 来解决这些限制:一个基于技能的综合基准测试,由两个子集 Gecko(R) 和 Gecko(S) 组成,其中提示用图 1 面板 (a) 中列出的技能进行标记。Gecko(R) )是通过从[10]中的现有数据集重新采样来获得更全面的技能分布(见图2)。 Gecko(S) 是半自动开发的,对于每项技能,我们手动设计一组子技能,以细粒度的方式探测模型的能力。













演示——附工程文件-220x150.jpg)









